- What is Exabeam?
- Welcome to the Advanced Analytics Homepage
- High-Level Counters on the Advanced Analytics Homepage
- About the Notable Users List
- Watchlists
- Account Lockouts List on the Advanced Analytics Homepage
- Navigate to Other Pages, Sign Out, or Change Password from the Advanced Analytics Homepage
- Use Dark Mode in Advanced Analytics , Case Manager, and Incident Responder
- Change Language in Advanced Analytics, Case Manager, and Incident Responder
- Get to Know a User Profile
- 1 General Information
- 2 Data Insights
- 3 Active Incident(s)
- 4 User Risk Trend
- 5 Risk Reasons
- Get to Know the User Timeline Page
- Examine Events by Category with the User Session Summary
- About the User Session Timeline
- Filter User Timelines
- View Activity Summary on a Specific Day
- Get to Know the Daily Timeline
- View and Understand an Account Lockout Sequence
- Get to Know the Account Lockout Sequence Timeline
- Accepting a Session or Sequence
- Search for a Data Lake Log from an Advanced Analytics Smart Timelines™ Event
- View a Data Lake Log from an Advanced Analytics Smart Timelines™ Event
- Download a Data Lake Log from an Advanced Analytics Smart Timelines™ Event
- Copy Advanced Analytics Event Data to Your Clipboard
- Search Splunk Logs from an Advanced Analytics Smart Timeline™ Session
- Add Advanced Analytics Evidence to a Case Manager Incident
- Entity Analytics
- Get Started with the Asset Page
- Get Started With the Threat Hunter Page
- Search Histograms Using the Data Insights Page
- Monitor Exabeam Processes Using the System Health Page
- Contact Technical Support
Monitor Exabeam Processes Using the System Health Page
System Health monitors Exabeam’s various processes and assists Exabeam engineers with troubleshooting. You can navigate to the System Health page from the menu icon at the top right corner of the homepage.
System Health is broken down into two sections: Health Status and System Activity.
System Activity shows each stage of the Exabeam pipeline and its current status. Expand any section to see more details about the state of a particular procedure.
Health Status is an on-demand assessment of the Exabeam pipeline. It is broken down into three categories:
General Health – General health tests that all of the back-end services are running - database storage, log feeds, snapshots, CPU, and memory.
Connectivity – Checks that Exabeam is able to connect to external systems, such as LDAP and LMS.
Log Feeds – This section reports on the health of the DC, VPN, Security Alerts, Windows Servers, and session management logs.
In all of the above areas GREEN indicates the status is good, YELLOW for a warning, and RED if the system is critical.
If there is a critical status on this page we recommend reaching out to Exabeam support.
Health Check
Advanced Analytics has improved the robustness of health checks by providing visibility on the backend data pipeline. All of the below health checks are configurable, please see the Advanced Analytics Administration Guide for more details.
New proactive health checks include:
In a multi-node environment processing current logs, when the worker node is lagging more than 6 hours behind the master node, a proactive notification will appear.
In a multi-node environment processing historical logs, when the worker node is lagging more than 48 hours behind the master node, a proactive notification will appear.
If an environment has been configured to receive syslog, but has not been receiving them for 1 hour, a proactive notification will appear.
In addition to new health checks, the health notifications are machine parseable and formatted. The format can be defined via configuration (e.g., JSON) and each notification type can have its own format configuration. For example, you can define a different configuration for an email alert versus a syslog notification. Each health check has a clearly defined description of what is being measured, the corresponding value, as well as the alert severity.
Configure Alerts for Worker Node Lag
When processing current or historical logs, an alert will be triggered when the worker node is falling behind the master node. How far behind can be configured in /opt/exabeam/config/tequila/custom/health.conf. The parameters are defined below:
RTModeTimeLagHours- During real-time processing the default setting is 6 hours.HistoricalModeTimeLagHours- During historical processing the default setting is 48 hours.syslogIngestionDelayHour- If processing syslogs, the default setting is 2 hours.
Disaster Recovery Health Alerts
For organizations that employ a disaster recovery configuration, on-demand and proactive health alerts are provided in the Health Page of Advanced Analytics.
Health Checks:
Progress of the replication between the primary and secondary clusters.
Status of the replication service and the most recent timestamp of replication for the different replication components.
The Disaster Recovery mode that the cluster is running in. Status are: Normal Mode or Failover Mode.
Health Alerts:
Alert notification to administrators if the replication service is not running.
Alerts for Storage Use
Available on the System Health page, the Storage Usage tab provides details regarding the current data retention settings for your Advanced Analytics deployment. Advanced Analytics sends notifications when available storage capacity dwindles to a critical level. Admins have the option to enable and configure automatic data retention and data purging for both HDFS and MongoDB usage.
Default Data Retention Settings
The table below lists default retention periods for data elements in your Advanced Analytics deployment:
| |||||
|---|---|---|---|---|---|
Logs | Original logs | 90 days | |||
Events on Disk | Parsed events on disk | 180 days | |||
Events in Database | Parsed events in the database | 180 days | |||
Triggered Rules and Sessions in Database | Container and triggered rule collections in the database | 365 days | |||
System Optimization
This tab is a single aggregated page for auditing and viewing disabled data types, including:
Disabled Models – When a model takes up too much memory, it is disabled and listed here. Re-enabling these models can cause the system to suffer performance issues.
Disabled Event Types – When a high volume user or asset amasses a large number of events of a certain event type, and that event type contributes to a large portion of the overall event count for that user the event type is automatically disabled and listed here.
Disabled Parsers – Advanced Analytics automatically identifies poor parser performance and disables such parsers in order to preserve the system health.
System Load Redistribution – Advanced Analytics automatically identifies overloaded worker nodes, and then takes corrective action by evenly redistributing the load across the cluster.
Critical Alerts, Warnings, and Error Messages
Although all notifications appear on the System Health page, there are two additional ways the Advanced Analytics UI provides better visibility on critical alerts, warnings, and error messages.
When a critical notification is generated, a banner will appear at the top of the UI. It contains specific information about the source of the warning or error, what the user and/or admin should do to correct the potential problem, and any helpful links to relevant knowledge base articles.
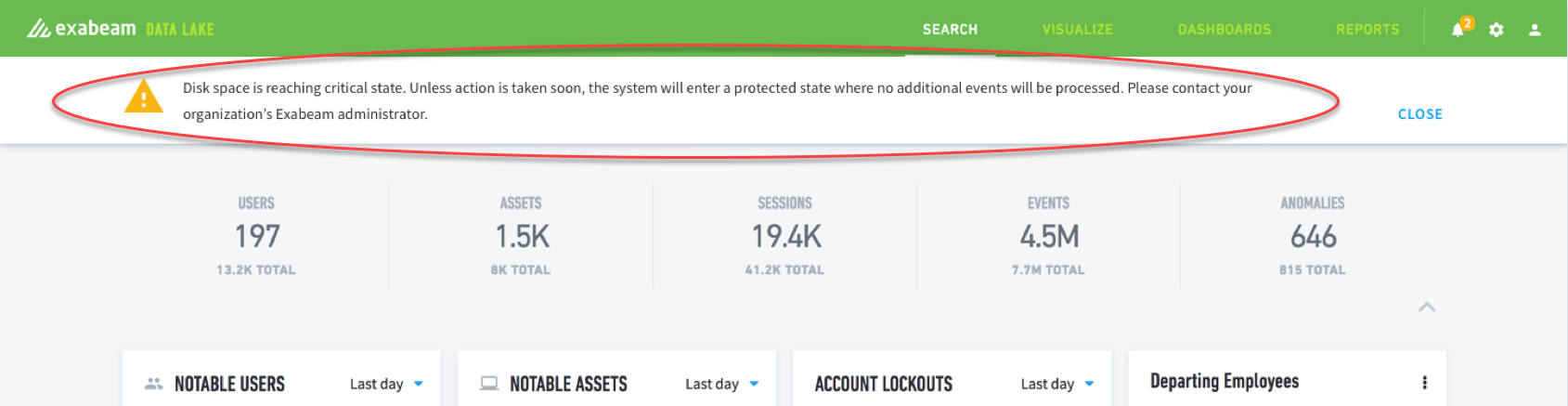
Depending on the level of the warning and user type (either administrator or user), the banner includes buttons to Close (i.e., dismiss) the banner and/or read an article containing important information about the message.

Additionally, a message box for critical notifications that require administrator decisions or multiple tasks to fix will appear upon admin login.
These message boxes include buttons to Close (i.e., dismiss) the banner and/or read an article containing important information about the message.
 |