- Exabeam Data Lake Architecture Overview
- Exabeam Product Deployment in On-premises or Virtual Environments
- Administrator Operations
- User Management
- Universal Role-Based Access
- Legacy Role-Based Access Control
- Exabeam Data Lake Object-based Access Control
- Exabeam Data Lake Secured Resources Overview
- Audit Log Management in Data Lake
- Set Up LDAP Server
- Azure AD Context Enrichment
- Set Up LDAP Authentication
- User Password Policies
- User Engagement Analytics Policy
- Exabeam Threat Intelligence Service
- Threat Intelligence Service Prerequisites
- View Threat Intelligence Feeds
- Threat Intelligence Context Tables
- View Threat Intelligence Context Tables
- Assign a Threat Intelligence Feed to a New Context Table
- Create a New Context Table from a Threat Intelligence Feed
- Using Threat Intelligence Service with Data Lake
- Check ExaCloud Connector Service Health Status
- Index Management
- Parser Management
- Forwarding to Other Destinations
- Syslog Forwarding Management in Exabeam Data Lake
- Syslog Forwarding Destinations
- Configure Log Forwarding Rate
- How to Forward Syslog to Exabeam Advanced Analytics from Exabeam Data Lake
- How to Forward Syslog from Exabeam Data Lake to Non-Exabeam External Destinations
- Exabeam Data Lake Selective Forwarding using Conditions
- How to Configure Exabeam Data Lake Log Destinations for Correlation Rule Outcomes
- Forward Exabeam Data Lake Incident to Exabeam Incident Responder
- Syslog Forwarding Management in Exabeam Data Lake
- Cluster Operations
- Cross-cluster Search in Exabeam Data Lake
- Prerequisites for Exabeam Data Lake Cross-cluster Search
- Remote Cluster Management for Exabeam Data Lake Cross-cluster Search
- Register a Remote Cluster in Exabeam Data Lake for Cross-cluster Search
- Exabeam Data Lake Cross-cluster Health Monitoring and Handling
- How to Enable/Disable/Delete Exabeam Data Lake Remote Clusters for Cross-cluster Search
- Exabeam Data Lake Remote Cluster Data Access Permissions for Cross-cluster Search
- Exabeam Cloud Telemetry Service
- System Health Page
- A. Technical Support Information
- B. List of Exabeam Services
- C. Network Ports
- D. Supported Browsers
Exabeam Data Lake Architecture Overview
Data Lake is one of three elements in the Exabeam Security Operations Platform and the data ingested by Data Lake can be used by Advanced Analytics for analysis and Incident Responder while investigating incidents.
At a high level, Data Lake involves these main processes:
Log collection
Log processing
Data presentation (searching, visualizing, reporting, dashboards, etc)
The system flow begins with the log collectors, which deployed either on the Data Lake server (for example, agent collector, Exabeam Site Collector, Exabeam Cloud Connector, database collector, Cisco eStreamer) or at local machines, collecting operational data, system metrics, and more. The Log Collectors then send those logs to the Log Ingestor.
The Log Ingestor can consume events from log collectors, syslog sources, or an existing SIEM. The log ingestor provides flow control and pushes the logs to the log indexer.
The log indexer is responsible for parsing and enriching before indexing and storing the logs in a distributed search cluster.
Data Lake is offered for hardware and virtual deployments as well as for SaaS.
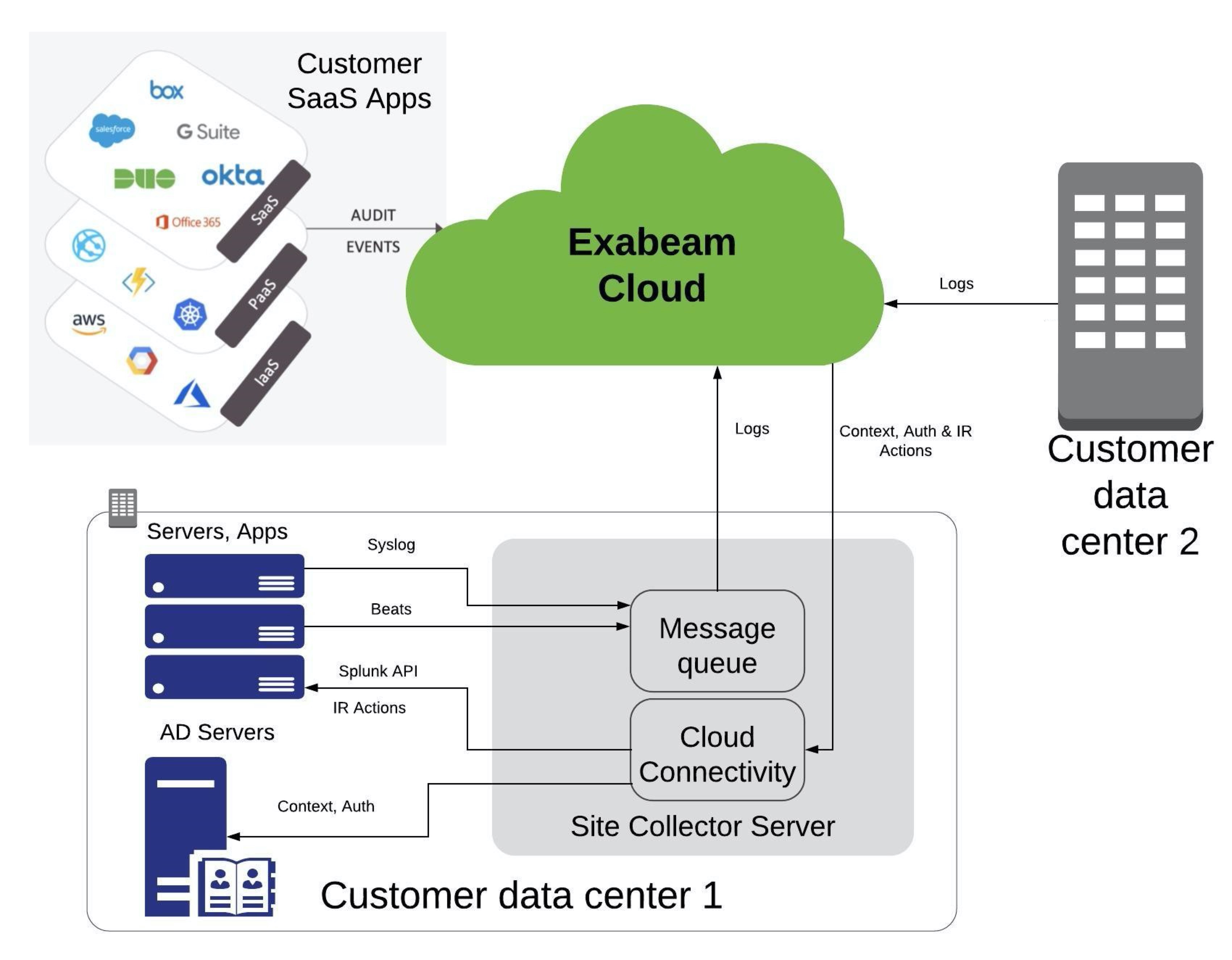 |
How Exabeam Data Lake Works
Data Lake indexes data from the servers, applications, databases, network devices, virtual machines, and so on, that make up your IT infrastructure. Data Lake can collect the data from machines located anywhere, whether it is local, remote, or cloud. Most users connect to Data Lake through a web browser to run searches and create dashboards. Other forms to connect to Data Lake include API streams from log collectors and ingestors. Additionally, Data Lake can push parsed logs to Exabeam Advanced Analytics or your SIEM.
Component | Description |
|---|---|
Exabeam Log Collectors | Agent/Server-based log collectors, SaaS collectors, and cloud connectors |
Exabeam Log Ingestor | Consumes events from Syslog and Connectors, providing flow control before pushing to the Log Processor |
Exabeam Log Processor | Responsible for parsing, enriching, and indexing log events that are then stored in a distributed cluster |
Exabeam Data Lake UI | The Web interface used for searching log events, creating charts, and viewing dashboards |
Exabeam Log Collectors in Data Lake
Data Lake can collect the data from machines located anywhere, whether it is local, remote, or cloud. It provides an out-of-the-box, file-based collector and Windows event collector. It also supports organizations that collect:
Data from devices communicating via the Cisco eStreamer protocol (see Data Lake Collector Guide > "Cisco eStreamer Log Collector in Exabeam Data Lake" for more information)
Data from API based connectors (see Exabeam Site Collector Guide for more information)
Logs via cloud applications (PaaS, IaaS, and SaaS)
Logs via databases
Most customer environments will utilize a combination of both server-side and agent connectors.
We can deploy and run local agents on machines from which logs must be collected and aggregated. We can also receive Syslog messages that are sent to our Log Ingestor from your SIEM or another third-party security service such as FireEye, Symantec, and many others.
Regardless of the method by which Data Lake collects logs, once they are accepted by the Log Ingestor they are treated exactly the same.
Note
Data Lake is optimized to support up to 1,500 collectors for clusters with 2 or more hosts. For single host clusters, up to 700 collectors is supported. There may be up to a 10% EPS performance degradation and up to a 20% increase in search latency, based on the number of collectors.
Exabeam Data Lake Agent Collector
Exabeam supports three types of agents for log collection:
Windows Log Collectors – Installed on Windows machines.
File Log Collectors – Installed on Windows or Linux machines.
Gzip Log Collectors – Installed on Windows or Linux machines.
These are lightweight processes that are installed on machines (i.e. workstations, servers) to capture operational data such as hardware events, security system events, application events, operating system metrics, network packets, health metrics, etc. The connectors read from one or more event logs and Gzipped logs. The connectors watch the event logs and send any new events in real time. The read position is persisted in order to allow the connectors to resume after restarts.
While file log collectors can be installed on Windows machines, they will only collect file inputs and will not collect windows event logs. If you would like to capture Windows event logs you must install Windows Event collectors.
Gzip file collectors process Gzipped files and publish them to Exabeam Data Lake.
Exabeam Data Lake Server Side Collector
Direct log collection is supported on Data Lake. Essentially, as long as there is a way to send syslog from a device (such as Windows or Unix servers) or a security solution (such as a DLP solution), Data Lake can ingest them. Alternatively, Data Lake can remotely connect to databases and Cisco eStreamer to fetch logs. In addition, Data Lake can also ingest logs from any device capable of sending Syslog (e.g. DLP, Firewall).
Data Lake supports data collection from the following log sources:
Syslog
DB Collectors for MySQL, MS-SQL, Oracle, PostgreSQL
eStreamer
Through Cisco eStreamer Collectors, Data Lake provides the ability for organizations to collect data from their Cisco FireSight systems. Like the three collectors mentioned above, the eStreamer collector is a service that runs on the Data Lake appliance and connects to the remote servers communicating over the Cisco eStreamer protocol.
Exabeam Data Lake Ingestor
The Data Lake Ingestion Engine serves as an aggregator, accepting logs via Syslog or via Log Collectors. It supports a variety of inputs that simultaneously pull in events from a multitude of common sources, unifying your data regardless of format or schema.
Data Lake processes streams of records as they occur and builds real-time streaming data pipelines that reliably move data between systems. It organizes all the incoming logs and builds a message queue to the Indexer, buffering and controlling the volume of logs coming into the Indexer.
Warning
Data Lake architecture is optimized to ingest log events that are less than 1 MB per event. This is a high safety limit that many customers will never hit. Please contact Exabeam Customer Success to assist in fine tuning this value.
Syslog- The Ingestor will accept syslog via a syslog ingestor instance listening on multiple ports and protocols. The messages will be written to a Kafka message queue. We highly recommend the use of a load balancer to distribute your syslog data across your various nodes in the Data Lake cluster. The collector will accept syslog via TLS on ports 515/TCP and 514/TCP or /UDP. The messages will be forwarded to a message queue.
Collectors- These are deployed on customer systems or Data Lake clusters and will send messages to Data Lake directly.
Exabeam Data Lake Processor
The Data Lake Processor accepts raw logs from the Ingestor and then parses relevant information from each log, enriches the data with contextual information, then indexes each log for full-text searching in near real time. The processor dynamically transforms and prepares your data regardless of format or complexity.
Parsing
One of the purposes of indexing data is to turn verbose messages into user-readable data structures. Data Lake extracts pre-defined fields from the logs by running them through a series of parsers. Log events are “typed” as defined by the parsers. For example, a Windows 4624 event from any collector such as Splunk or Exabeam Cloud Connector would be “typed” as windows-4624.
The original log data, along with the parsed fields, are searchable.
Indexing
Indexing normalizes log data and builds a metadata structure to optimize searches. It is be developed from parsed logs with or without enrichment tags.