- Advanced Analytics
- Understand the Basics of Advanced Analytics
- Deploy Exabeam Products
- Considerations for Installing and Deploying Exabeam Products
- Things You Need to Know About Deploying Advanced Analytics
- Pre-Check Scripts for an On-Premises or Cloud Deployment
- Install Exabeam Software
- Upgrade an Exabeam Product
- Add Ingestion (LIME) Nodes to an Existing Advanced Analytics Cluster
- Apply Pre-approved CentOS Updates
- Configure Advanced Analytics
- Set Up Admin Operations
- Access Exabeam Advanced Analytics
- A. Supported Browsers
- Set Up Log Management
- Set Up Training & Scoring
- Set Up Log Feeds
- Draft/Published Modes for Log Feeds
- Advanced Analytics Transaction Log and Configuration Backup and Restore
- Configure Advanced Analytics System Activity Notifications
- Exabeam Licenses
- Exabeam Cluster Authentication Token
- Set Up Authentication and Access Control
- What Are Accounts & Groups?
- What Are Assets & Networks?
- Common Access Card (CAC) Authentication
- Role-Based Access Control
- Out-of-the-Box Roles
- Set Up User Management
- Manage Users
- Set Up LDAP Server
- Set Up LDAP Authentication
- Third-Party Identity Provider Configuration
- Azure AD Context Enrichment
- Set Up Context Management
- Custom Context Tables
- How Audit Logging Works
- Starting the Analytics Engine
- Additional Configurations
- Configure Static Mappings of Hosts to/from IP Addresses
- Associate Machine Oriented Log Events to User Sessions
- Display a Custom Login Message
- Configure Threat Hunter Maximum Search Result Limit
- Change Date and Time Formats
- Set Up Machine Learning Algorithms (Beta)
- Detect Phishing
- Restart the Analytics Engine
- Restart Log Ingestion and Messaging Engine (LIME)
- Custom Configuration Validation
- Advanced Analytics Transaction Log and Configuration Backup and Restore
- Reprocess Jobs
- Re-Assign to a New IP (Appliance Only)
- Hadoop Distributed File System (HDFS) Namenode Storage Redundancy
- User Engagement Analytics Policy
- Configure Settings to Search for Data Lake Logs in Advanced Analytics
- Enable Settings to Detect Email Sent to Personal Accounts
- Configure Smart Timeline™ to Display More Accurate Times for When Rules Triggered
- Configure Rules
- Exabeam Threat Intelligence Service
- Threat Intelligence Service Prerequisites
- Connect to Threat Intelligence Service through a Proxy
- View Threat Intelligence Feeds
- Threat Intelligence Context Tables
- View Threat Intelligence Context Tables
- Assign a Threat Intelligence Feed to a New Context Table
- Create a New Context Table from a Threat Intelligence Feed
- Check ExaCloud Connector Service Health Status
- Disaster Recovery
- Manage Security Content in Advanced Analytics
- Exabeam Hardening
- Set Up Admin Operations
- Health Status Page
- Troubleshoot Advanced Analytics Data Ingestion Issues
- Generate a Support File
- View Version Information
- Syslog Notifications Key-Value Pair Definitions
Understand the Basics of Advanced Analytics
Get to know the foundations of Advanced Analytics, such as Context, Logs, and the Risk Engine. Understand the overall architecture, and how all the parts work together.
Advanced Analytics High-level Overview
Note
This overview applies to Advanced Analytics versions i60–i62.
Exabeam Advanced Analytics provides user and entity behavior intelligence on top of existing SIEM and log management data repositories to detect compromised and rogue insiders and present a complete picture of the user session and lateral movement use in the attack chain.
Exabeam pulls logs from a variety of data sources (Domain Controller, VPN, security alerts, DLP etc.) through your existing SIEM, as well as direct ingestion via Syslog, and enriches this data with identity information collected from Active Directory (LDAP). This provides an identity context for credential use. Using behavior modeling and analytics, Exabeam learns normal user credential activities, access characteristics, and automatically asks questions of the data to expose anomalous activities.
Finally, Exabeam places all user credential activities and characteristics on a timeline with scores assigned to anomalous access behavior. Traditional security alerts are also scored, attributed to identities, and placed on the activity timeline. All systems touched by compromised credentials of insiders are identified to reveal the attacker's path through the IT environment.
The figure below gives a visual representation of the high-level components of the Exabeam solution.
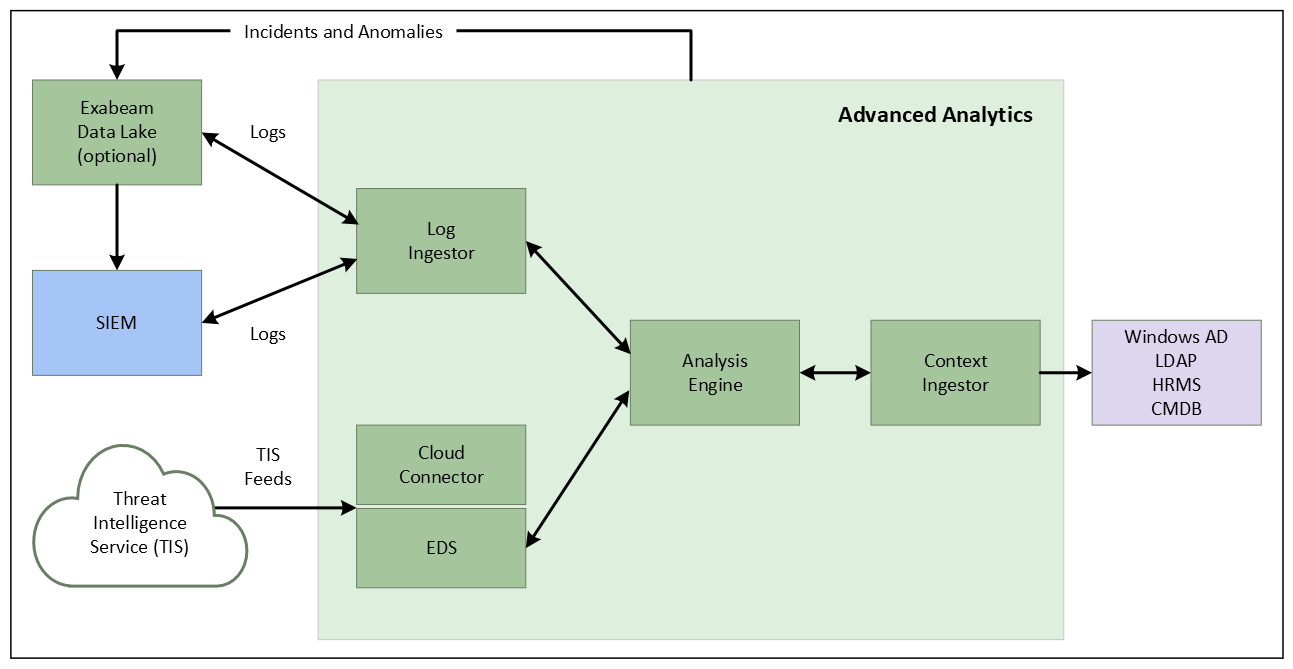
How Advanced Analytics Works
Exabeam has a two-level approach to identifying incidents. The first layer collects data from log management systems and external context data sources. The second layer consists of a risk engine and Exabeam's Stateful User TrackingTM.
The first layer normalizes the events and enriches them with contextual information about the users and assets in order to understand the entity activities within the environment across a variety of dimensions. At this layer, the statistical modeling profiles the behaviors of the network entities and machine learning is applied in the areas of context estimation, for example, to distinguish between users and service accounts.
In the second layer, as events flow through the processing engine, Exabeam uses Stateful User TrackingTM to connect user activities across multiple accounts, devices, and IP addresses. It places all user credential activities and characteristics on a timeline with scores assigned to anomalous access behavior. Traditional security alerts are also scored, attributed to identities, and placed on the activity timeline. The risk engine updates risk scores based on input from the anomaly detection layer as well as from other external data sources. The risk engine brings in the security knowledge and expertise in order to bubble up significant anomalies. Incidents are generated when scores exceed defined thresholds.
Fetch and Ingest Logs
Exabeam can fetch logs from SIEM log repositories and also ingest logs via Syslog. We currently support log ingestion from Splunk, Microfocus ArcSight, IBM QRadar, McAfee ESM and RSA Security Analytics, as well as other data sources such as Exabeam Data Lake. For Splunk and QRadar log ingestion is via external API's and Syslog is used for all others. For SIEM solutions, such as LogRhythm, McAfee ESM, and LogLogic, we ingest via Syslog forwarding.
Add Context
Logs tell us what the users and entities are doing while context tells us who the users and entities are. These are data sources that typically come from identity services such as Active Directory. They enrich the logs to help with the anomaly detection process or are used directly by the risk engine layer for fact-based rules. Regardless of where these external feeds are used, they all go through the anomaly detection layer as part of an event. Examples of context information potentially used by the anomaly detection layer are the location for a given IP address, ISP name for an IP address, and department for a user. We can also feed contextual information from HR Management Systems, Configuration Management Databases, Identity Systems, etc. Another example of contextual information would be threat intelligence feeds, which would be used by the anomaly detection layer to check if a specific IP is listed in a threat intelligence feed.
Detect Anomalies
This component uses machine learning algorithms to identify anomalous behaviors. The anomalies may be relative to a single user, session, or device, or relative to group behavior. For example, some anomalies may refer to a behavior that is anomalous for a user relative to their past history, and other anomalies may take into account anomalous behaviors relative to people with roles similar to the individual (peer group), location, or other grouping mechanisms.
The algorithms are constantly improved upon to increase the speed and accuracy of numerical data calculations. This in turn improves the performance of Advanced Analytics.
Assess Risk Using the Risk Engine
The risk engine treats each session as a container and assigns risk scores to the events that are flagged as anomalous. As the sum of event risk scores reach a threshold (a default value of 90), incidents are automatically generated within the Case Management module or escalated as incidents to an existing SIEMs or ticketing systems. The event scores are also available for the user to query through the user interface. In some cases, the scores reflect not only information considered as anomalous by Exabeam based only on behavior log feeds, but it can provide an Exabeam score in connection to other security alerts that may be generated by third-party sources (for example, FireEye or CrowdStrike alerts). These security alerts are integrated into user sessions and scored as factual risks.
The Advanced Analytics Architecture
Note
The architecture described in this section applies to Advanced Analytics versions i60–i62.
Exabeam has a scale-out architecture that is a cluster of nodes that meets the needs of small to global organizations. Customers can start with a single node Exabeam appliance or a cluster of multiple nodes based on the number of active users and the volume of logs processed by the Exabeam engine. Smaller organizations can function on a single node appliance while for larger organizations we can scale horizontally by adding multiple nodes as needed. A node can be a physical appliance or a virtual appliance. Distributing the processing across multiple CPU cores and nodes allows Exabeam to support not only environments with many employees but also high-volume feeds, such as end-point logs or web activity (proxy) logs. Figure 1 shows the Exabeam architecture and the components that run inside the cluster.
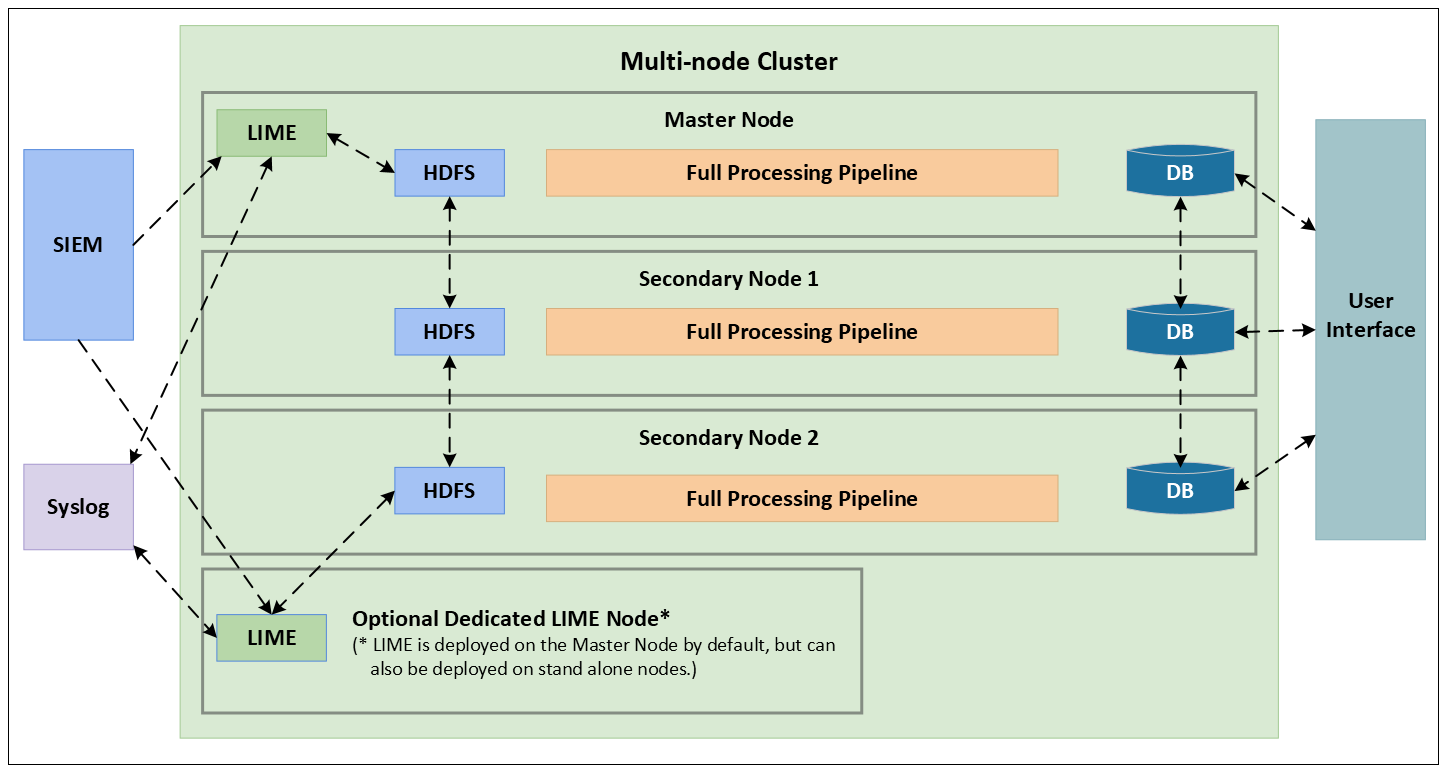
LIME (Log Ingestion and Message Extraction): LIME runs on the Master node or a standalone node (depending on the log volume). It is the Exabeam process that interfaces with Exabeam Data Lake or an alternative customer log repository; it fetches the data or receives via Syslog and stores it on HDFS. In addition, it also normalizes the raw logs into events that the rest of the Exabeam pipeline can process. After parsing the events, it places the parsed events into HDFS, where the Master and Slave Nodes will retrieve them for pipeline processing.
HDFS (Hadoop Distributed File System): This is a distributed file system, which organizes file and directory services of individual servers into a global directory in such a way that remote data access is not location-specific but is identical from any client. All files are accessible to all users of the global file system and organization is hierarchical and directory-based. Distributed file systems typically use file or database replication (distributing copies of data on multiple servers) to protect against data access failures. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. It is highly fault-tolerant and enables streaming access to file system data. This is where Exabeam stores the raw logs that are fetched from the SIEM and Syslog, as well as the parsed events that are accessed by the nodes for processing. These files are available to all nodes.
Docker Containers: Each major component of Exabeam (such as LIME, Analytics Engine, HDFS, etc.) is contained within a Docker container. Docker containers wrap up a piece of software in a complete file-system that contains everything it needs to run: code, run-time, system tools, system libraries – anything you can install on a server. This guarantees that it will always run the same, regardless of the environment it is running in.
Master Node: The master node is the powerful node of the cluster - it runs the processing pipeline and in a multi-node environment also coordinates the activities of the node cluster. The session manager runs on the master node and identifies all logs that belong to a session by putting together all the activities of a user from the time they logon to the time they logoff.
Worker Nodes: In a multi-node environment the Worker Nodes are responsible for processing all of the logs generated by high-volume feeds. The Worker Nodes run the Sequence Manager which processes all logs that belong to high volume feeds, such as proxy or endpoint logs.
Exabeam customers can begin with a Master node and add worker nodes as needed. If a cluster has only one node (which is the Master Node), then the node runs both the Session Manager and the Sequence Manager (if needed).
Distributed Database: All session, user, asset, and event metadata is sorted in a distributed Mongo database. The database is sharded in order to handle the higher volume of data and the logs stored in each shard are available to all nodes.
User Interface: Web Services for the user interface runs on the Master Node, though technically it can run on any. It retrieves data from the database.