- Advanced Analytics
- Understand the Basics of Advanced Analytics
- Deploy Exabeam Products
- Considerations for Installing and Deploying Exabeam Products
- Things You Need to Know About Deploying Advanced Analytics
- Pre-Check Scripts for an On-Premises or Cloud Deployment
- Install Exabeam Software
- Upgrade an Exabeam Product
- Add Ingestion (LIME) Nodes to an Existing Advanced Analytics Cluster
- Apply Pre-approved CentOS Updates
- Configure Advanced Analytics
- Set Up Admin Operations
- Access Exabeam Advanced Analytics
- A. Supported Browsers
- Set Up Log Management
- Set Up Training & Scoring
- Set Up Log Feeds
- Draft/Published Modes for Log Feeds
- Advanced Analytics Transaction Log and Configuration Backup and Restore
- Configure Advanced Analytics System Activity Notifications
- Exabeam Licenses
- Exabeam Cluster Authentication Token
- Set Up Authentication and Access Control
- What Are Accounts & Groups?
- What Are Assets & Networks?
- Common Access Card (CAC) Authentication
- Role-Based Access Control
- Out-of-the-Box Roles
- Set Up User Management
- Manage Users
- Set Up LDAP Server
- Set Up LDAP Authentication
- Third-Party Identity Provider Configuration
- Azure AD Context Enrichment
- Set Up Context Management
- Custom Context Tables
- How Audit Logging Works
- Starting the Analytics Engine
- Additional Configurations
- Configure Static Mappings of Hosts to/from IP Addresses
- Associate Machine Oriented Log Events to User Sessions
- Display a Custom Login Message
- Configure Threat Hunter Maximum Search Result Limit
- Change Date and Time Formats
- Set Up Machine Learning Algorithms (Beta)
- Detect Phishing
- Restart the Analytics Engine
- Restart Log Ingestion and Messaging Engine (LIME)
- Custom Configuration Validation
- Advanced Analytics Transaction Log and Configuration Backup and Restore
- Reprocess Jobs
- Re-Assign to a New IP (Appliance Only)
- Hadoop Distributed File System (HDFS) Namenode Storage Redundancy
- User Engagement Analytics Policy
- Configure Settings to Search for Data Lake Logs in Advanced Analytics
- Enable Settings to Detect Email Sent to Personal Accounts
- Configure Smart Timeline™ to Display More Accurate Times for When Rules Triggered
- Configure Rules
- Exabeam Threat Intelligence Service
- Threat Intelligence Service Prerequisites
- Connect to Threat Intelligence Service through a Proxy
- View Threat Intelligence Feeds
- Threat Intelligence Context Tables
- View Threat Intelligence Context Tables
- Assign a Threat Intelligence Feed to a New Context Table
- Create a New Context Table from a Threat Intelligence Feed
- Check ExaCloud Connector Service Health Status
- Disaster Recovery
- Manage Security Content in Advanced Analytics
- Exabeam Hardening
- Set Up Admin Operations
- Health Status Page
- Troubleshoot Advanced Analytics Data Ingestion Issues
- Generate a Support File
- View Version Information
- Syslog Notifications Key-Value Pair Definitions
Health Status Page
The Health Status page offers an on-demand assessment of the Exabeam pipeline. The assessment has three categories:
General Health: General health tests that all of the back-end services are running - database storage, log feeds, snapshots, CPU, and memory.
Connectivity: Checks that Exabeam is able to connect to external systems, such as LDAP and SIEM.
Log Feeds: This section reports on the health of the DC, VPN, Security Alerts, Windows Servers, and session management logs.
In all of the categories, the statuses are color-coded as follows: GREEN = good, YELLOW = warning, and RED = critical.
Located on the homepage are the Proactive Health Checks that alert administrations when:
Any of the core Exabeam services are not running
There is insufficient disk storage space
Exabeam has not been fetching logs from the SIEM for a configurable amount of time
Proactive and On-Demand System Health Checks
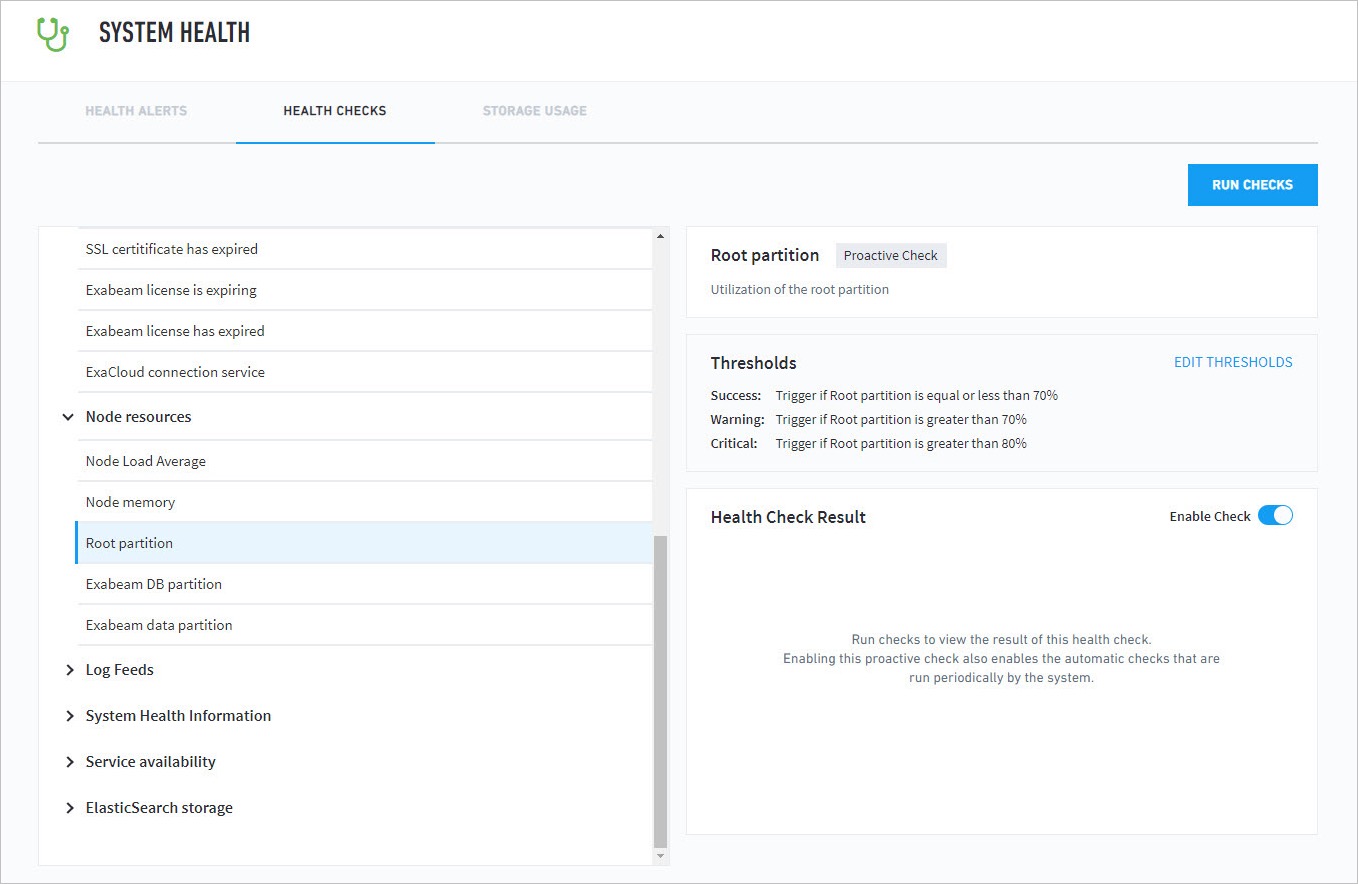
System Health is used to check the status of critical functionality across your system and assists Exabeam engineers with troubleshooting. Exabeam provides visibility on the backend data pipeline via Health Checks. Graphs and tables on the page visually represent the health status for all of the key systems, as well as indexes and the appliance, so you are always able to check statuses at a glance and track health over time.
Proactive health checks run automatically and periodically in the background.
On-demand health checks can be initiated manually and are run immediately. All newly gathered health check statuses and data is updated in the information panes on the page. All proactive and on-demand health checks are listed on the Health Checks page. Proactive health checks are visible by any user in your organization. Only users with administrator permission can reach the page.
 |
When a health check is triggered, a notification message is displayed in the upper right corner of the UI. Select the alert icon to open a side panel that lists the alerts and provides additional detail. A panel listing all notifications is expanded.
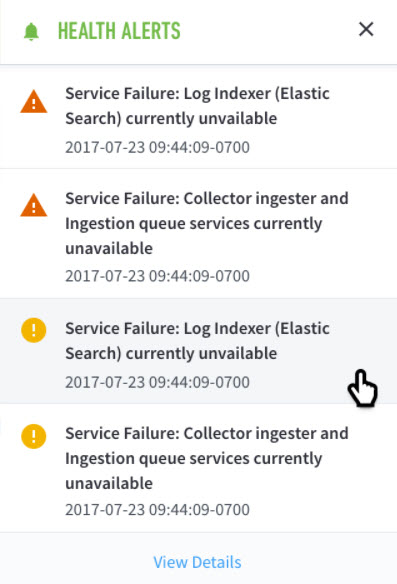 |
These alerts are also listed under the Health Alerts tab in the System Health page. In general:
Warning: There is an issue that should be brought to the attention of the user.
Critical: Immediate action is recommended. In all cases, if an alert is raised on your system, please contact Exabeam Customer Success.
To reach the Health Checks page, navigate to the System Health page from the Settings tab at the top right corner of any page, then select the Health Checks tab.
Health check categories are:
Service Availability – License expiration, database, disaster recovery, Web Common application engine, directory service, aggregators, and external connections
Node Resources – Load, performance, and retention capacity
Service Availability (Incident Processors and Repositories) - IR, Hadoop, and Kafka performance metrics
Advanced Analytics Specific Health Checks
Log Feeds – Session counts, alerts, and metrics
System Health Information – Core data and operations processor metrics
Elasticsearch Storage (Incident Responder) – Elasticsearch capacity and performance metrics
 |
Configure Alerts for Worker Node Lag
When processing current or historical logs, an alert will be triggered when the worker node is falling behind the master node. How far behind can be configured in /opt/config/exabeam/tequila/custom/health.conf. The parameters are defined below:
RTModeTimeLagHours- During real-time processing the default setting is 6 hours.HistoricalModeTimeLagHours- During historical processing the default setting is 48 hours.syslogIngestionDelayHour- If processing syslogs, the default setting is 2 hours.
}
slaveMasterLagCheck {
printFormats = {
json = "{ \"lagTimeHours\": \"$lagTimeHours\", \"masterRunDate\": \"$masterRunDate\", \"slaveRunDate\": \"$slaveRunDate\", \"isRealTimeMode\": \"$isRealTimeMode\"}"
plainText = "Worker nodes processing lagging by more than $lagTimeHours hours. Is in real time: $isRealTimeMode "
}
RTModeTimeLagHours = 6
HistoricalModeTimeLagHours = 48
}
limeCheck {
syslogIngestionDelayHour = 1
}System Health Checks
Martini Service Check: Martini is the name Exabeam has given to its Analytics Engine. In a multi-node environment, Martini will be the Master node.
Tequila Service Check: Tequila is the name Exabeam has given to its User Interface layer.
Lime Service Check: LIME (Log Ingestion and Message Extraction) is the service within Exabeam that ingests logs from an organization's SIEM, parses and then stores them in HDFS. The main service mode parses message files and creates one message file per log file. This mode is used to create message files that will be consumed by the main node.
Mongo Service Check: MongoDB is Exabeam's chosen persistence database. A distributed MongoDB system contains three elements: shards, routers, and configuration servers (configsvr). The shards are where the data is stored; the routers are the piece that distributes and collect the data from the different shards; and the configuration servers which tracks where the various pieces of data are stored in the shards.
Zookeeper Service Check: Zookeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. In a distributed multi-node environment, we need the ability to make a value change inside one process on a machine and have that change be seen by a different process on a different machine. Zookeeper provides this service.
Hadoop Service Check: Master - Hadoop is Exabeam's distributed file system, where the raw logs and parsed events are stored. These files are available to all nodes.
Ganglia Service Check: Ganglia is a distributed monitoring system for computing systems. It allows us to view live or historical statistics for all the machines that are being monitored.
License Checks: The status of your Exabeam license will be reported in this section. This is where you will find the expiration date for your current license.
Alerts for Storage Use
Available on the System Health page, the Storage Usage tab provides details regarding the current data retention settings for your Advanced Analytics deployment. Advanced Analytics sends notifications when available storage capacity dwindles to a critical level. Admins have the option to enable and configure automatic data retention and data purging for both HDFS and MongoDB usage.
For more information on data retention, see Data Retention in Advanced Analytics.
Default Data Retention Settings
Default Advanced Analytics data retention settings depend on the license you purchased. For licensing information, see Product Entitlements on the Exabeam Community site.
System Health Alerts for Low Disk Space
Get notified when your disk is running low on space.
Your Advanced Analytics system may go down for several hours when it upgrades or restarts. During this down time, your log source continues to send logs to a disk, accumulating a backlog of unprocessed logs. Log Ingestion and Messaging Engine (LIME) tries to process this backlog when it starts running again. If your log source sends logs faster than what your system size can handle, LIME may struggle to process these logs, run out of disk space, and stop working correctly.
Your Advanced Analytics system already uses mechanisms, like compressing files, to conserve as much space as possible. If your disk is still running out of space, you receive system health alerts.
If LIME is running, you receive two system health alerts. When the disk has 25 percent capacity remaining, the first health alert notifies you that you're running low on disk space. In the rare case that your disk has 15 percent capacity remaining, a second health alert notifies you that your system has deleted files, starting with the largest one, as a last resort to keep your system running.
If LIME goes down, Advanced Analytics can't send health alerts. When LIME is running again, you may receive a belated health alert. In the rare case that your disk reached 15 percent remaining capacity while LIME was down, this health alert notifies you that your system has deleted files, starting with the largest one, as a last resort to keep your system running.
When you receive these health alerts, consider tuning your system so it ingests less logs or ingests logs more slowly. If you ingest logs from Data Lake, consider setting a lower log forwarding rate.
System Health Alerts for Paused Parsers
Get notified automatically when Advanced Analytics pauses a parser.
To protect your system from going down and ensure that it continues to process data in real time, Advanced Analytics detects when a parser is taking an abnormally long time to parse a log, then pauses it.
When Advanced Analytics pauses a parser, you receive a health alert that describes which parser was paused, on which node, and recommended actions you could take. When Advanced Analytics pauses additional parsers, it resolves the existing health alert and sends a new alert that lists all paused parsers.
Advanced Analytics also resolves an existing health alert any time you restart the Log Ingestion and Messaging Engine (LIME) and resume a paused parser. For example, if you change the threshold for when parsers get paused, you must restart LIME, which resumes any paused parsers and prompts Advanced Analytics to resolve any existing health alerts. If a resumed parser continues to perform poorly, Advanced Analytics pauses it again and sends another health alert about that parser.
View Storage Usage and Retention Settings
By default, Advanced Analytics implements data retention settings for logs and messages. This allows the system to automatically delete old data, which reduces chances of performance issues due to low repository space.
Available on the System Health page, the Storage Usage tab provides details regarding the current data retention settings for your Advanced Analytics deployment, including:
HDFS Data Retention – Number of days the data has been stored, the number of days remaining before it is automatically deleted, and a toggle to enable/disable auto-deletion of old data.
Note
If enabling or disabling Auto-delete Old Data, you must also restart the Log Ingestion Engine before the change goes into effect.
A warning message appears if the average rate of HDFS usage exceeds the intended retention period.
HDFS Usage – Total HDFS usage, including specific breakdowns for logs, events on disk, and events in database .
Note
The Volume field displays the compressed index size on disk for storage planning. This differs from the total consumption of daily ingested logs used for billing.
MongoDB Retention – A dialog to set retention settings and a toggle to enable/disable disk-based deletion of old data.
You can edit the MongoDB data retention settings by clicking the pencil icon.
The capacity used percentage threshold is set to 85% by default, with a maximum value of 90%. It helps to prevent MongoDB from reaching capacity before hitting the default retention period threshold. As soon as MongoDB meets the percentage on any node, the system will start purging events until it is back below the capacity used threshold.
The maximum length of your retention period depends on the license you purchased. For licensing information, see Product Entitlements on the Exabeam Community site.
Note
The Days for Triggered Rules & Sessions value cannot be less than the Days for Events value.
MongoDB Usage – Total MongoDB usage.
Set Up System Optimization
This tab is a single aggregated page for auditing and viewing disabled data types (including models, event types, and parsers) and system load redistribution.
Disabled Models
When a model takes up too much memory, it is disabled. If you enable these models, the system may suffer performance issues.
Note
Exabeam disables models as a last resort to ensure system performance. We have other defensive measures to prevent models from using all of the system's memory. These measures include enabling model aging and limiting the model bin size count. If these safeguards cannot prevent a model from consuming too much memory, the system prevents itself from shutting down as it runs out of memory.
Configure Model Maximum Bin Limit
Hardware and Virtual Deployments Only
Models are disabled once they reach their maximum bin limit. You can either set a global configuration for the maximum number of bins or an individual configuration for each model name.
This is done by setting a max number of bins, MaxNumberOfBins in exabeam_default.conf or the model definition, for categorical models. The new limit is 10 million bins, although some models, such as ones where the feature is "Country" have a lower limit. We have put many guardrails in place to make sure models do not consume excessive memory and impact overall system health and performance. These include setting a maximum limit on bins, enabling aging for models, and verifying data which goes into models to make sure it is valid. If a model is still consuming excessive amounts of memory then we will proceed to disable that model.
To globally configure the maximum bin limit, navigate to the Modeling section located in the exabeam_default.conf file at /opt/exabeam/config/default/exabeam_default.conf.
All changes should be made to /opt/exabeam/config/custom/custom_exabeam_config.conf:
Modeling {
...
# To save space we limit the number of bins saved for a histogram. This defaults to 100 if not present
# This parameter is only for internal research
MaxSizeOfReducedModel = 100
MaxPointsToCluster = 250
ReclusteringPeriod = 24 hours
MaxNumberOfBins = 1000000Additionally, it is possible to define a specific bin limit on a per model basis via the model definition section in the models.conf file at /opt/exabeam/config/custom/models.conf. Here is an example model, where MaxNumberOfBins is set to 5,000,000:
WTC-OH {
ModelTemplate = "Hosts on which scheduled tasks are created"
Description = "Models the hosts on which scheduled tasks are created"
Category = "Asset Activity Monitoring"
IconName = ""
ScopeType = "ORG"
Scope = "org"
Feature = "dest_host"
FeatureName = "host"
FeatureType = "asset"
TrainIf = """count(dest_host,'task-created')=1"""
ModelType = "CATEGORICAL"
BinWidth = "5"
MaxNumberOfBins = "5000000"
AgingWindow = ""
CutOff = "10"
Alpha = "2"
ConvergenceFilter = "confidence_factor>=0.8"
HistogramEventTypes = [
"task-created"
]
Disabled = "FALSE"
}Paused Parsers
If your parser takes too long to parse a log and meets certain conditions, Advanced Analytics pauses the parser.
To keep your system running smoothly and processing data in real time, Advanced Analytics detects parsers that are performing poorly, then pauses them. Your parsers may perform poorly because:
In both cases, your system calculates whether the parser exceeds configured thresholds and meets certain conditions, then pauses the parser.
When a parser meets the conditions on a Log Ingestion and Messaging Engine (LIME) node, your system pauses the parser only on that node. If you have multiple LIME nodes, it is not automatically paused on all nodes unless it meets these conditions on every node.
When Advanced Analytics pauses a parser on any node, the parser appears in a of paused parsers. You receive a system health alert only for paused slow parsers, not stuck or failed parsers.
Conditions for Pausing Slow Parsers
To identify a slow parser, your system places the parser in a cache. Every configured period, OutputParsingTimePeriodInMinutes (five minutes by default), it calculates how long it takes, on average, for the parser to parse a log. It compares this average to a configurable threshold, ParserDisableThresholdInMills, in lime.conf.
To calculate a percentage of how much the parser makes up of the total parsing time, your system divides the previously-calculated average by the total time all parsers took to parse an event in the same five minute period. It compares the percentage to another configurable threshold, ParserDisableTimePercentage, in lime.conf.
Your system conducts a second round of checks if the parser meets certain conditions:
The average time it takes for the parser to parse a log exceeds a threshold,
ParserDisableThresholdInMills(seven milliseconds by default).The parser constitutes more than a certain percentage,
ParserDisableTimePercentage(50 percent by default), of the total parsing time of all parsers.
During another five-minute period, your system checks the parser for a second time. If the parser meets the same conditions again, your system pauses the parser.
If you have a virtual or hardware deployment, you can configure OutputParsingTimePerioidInMinutes, ParserDisableThresholdInMills, and ParserDisableTimePercentage to better suit your needs.
Conditions for Pausing Stuck Parsers
To identify a stuck parser, your system measures how long it takes for a parser to parse a log. If the time exceeds a threshold, StuckParserWaitTimeoutMillis (100 milliseconds by default), the parser fails with a timeout exception. Your system logs the error at a DEBUG security level and notes the parser in internal error statistics.
In each configured period, ParserMaxErrorTimeWindowForChecksMillis (9000 miliseconds, or 15 minutes, by default), your system checks the internal error statistics for any parsers that have accumulated a certain number of errors. If the errors exceed a threshold, ParserMaxErrorNumberThreshold (100 errors by default), the parser is paused and removed from the internal error statistics.
If you have a virtual or hardware deployment, you can configure StuckParserWaitTimeoutMillis, ParserMaxErrorTimeWindowForChecksMillis, and ParserMaxErrorNumberThreshold.
View Paused Parsers
To keep your system running smoothly and processing data in real time, Advanced Analytics detects slow or inefficient parsers, then pauses them. View all paused parsers in Advanced Analytics, under System Health, or in your system.
View Paused Parsers in Advanced Analytics
In the navigation bar, click the menu
 , then select System Health.
, then select System Health.Select the System Optimization tab.
Select Paused Parsers.
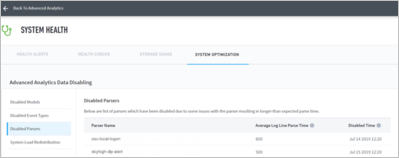
View a list of paused parsers, sorted alphabetically by parser name, and information about them, including:
Parser Name – The name of the paused parser.
Average Log Line Parse Time – Average time the parser took to parse each event.
Paused Time – Date and time when the parser was paused.
View Paused Parsers in Your System
If you a hardware or virtual deployment, you can view paused parsers in disabled_parsers_db.current_collection, located in the MongoDB database. Run:
bash$ sos; mongo mongos> use disable_parser_db mongos> db.current_collection.findOne()
For example, a paused parser collection may look like:
{
"_id" : ObjectId("5cf5bb9e094b83c6f7f89b86"),
"_id" : ObjectId("5cf5bb9e094b83c6f7f89b86"),
"parser_name" : "raw-4625",
"average_parsing_time" : 9.774774774774775,
"time" : NumberLong(1559608222854)
}Configure Conditions for Pausing Parsers
Hardware and Virtual Deployments Only
Change the conditions required for Advanced Analytics to pause slow, stuck, or failed parsers.
Configure Conditions for Pausing Slow Parsers
Change how Advanced Analytics defines and identifies parsers that are taking an abnormally long time to parse logs. You can change three variables: OutputParsingTimePeriodInMinutes, ParserDisableThresholdInMills, or ParserDisablePercentage.
If this is the first time you're changing this configuration, copy it from
lime_default.conftocustom_life_config.conf:Navigate to
/opt/exabeam/config/default/lime_default.conf, then navigate to theLogParsersection.Copy the
LogParsersection with the variables you're changing, then paste it in/opt/exabeam/config/custom/custom_lime_config.conf. For example:LogParser{ #Output parsing performance in debug mode, be cautious this might affect performance in parsing OutputParsingTime = true OutputParsingTimePeriodInMinutes = 5 AllowDisableParser = true // If this is enabled, output parsing time will be enabled by default. ParserDisableThresholdInMills = 7 //If average parsing time pass this threshold, we will disable that parser ParserDisableTimePercentage = 0.5 }
In
custom_lime_config.conf, changeOutputParsingTimePeriodInMinutes,ParserDisableThresholdInMills, orParserDisablePercentage.OutputParsingTimePeriodInMinutes– The intervals in which your system calculates a parser's average parse time and total parsing percentage. The value can be any integer, representing minutes.ParserDisableThresholdInMills– For a parser to be paused, its average parse time per log must exceed this threshold. The value can be any integer, representing millseconds.ParserDisablePercentage– For a parser to be paused, it must constitute more than this percentage of the total parsing time. The value can be any decimal between 0.1 and 0.9. The higher you set this percentage, the more severe the parsers you pause.
Save
custom_lime_config.conf.Restart Log Ingestion and Messaging Engine (LIME):
Source the shell environment:
source /opt/exabeam/bin/shell-environment.bash
Restart LIME:
lime-stop; lime-start
Configure Conditions for Pausing Stuck Parsers
Change how Advanced Analytics defines and identifies parsers that have gone into an infinite loop or failed with a non-timeout exception. You can change three variables: StuckParserWaitTimeoutMillis, ParserMaxErrorTimeWindowForChecksMillis, and ParserMaxErrorNumberThreshold.
If this is the first time you're changing this configuration, copy it from
lime_default.conftocustom_life_config.conf:Navigate to
/opt/exabeam/config/default/lime_default.conf, then navigate to theLogParsersection.Copy the
LogParsersection with the variables you're changing, then paste it in/opt/exabeam/config/custom/custom_lime_config.conf. For example:LogParser{ AllowProcessionOfStuckParser = false ParserMaxErrorNumberThreshold = 100 ParserMaxErrorTimeWindowForChecksMillis = 300000 // 5 minutes StuckParserWaitTimeOutMillis = 100 }
In
custom_lime_config.conf, changeStuckParserWaitTimeoutMillis,ParserMaxErrorTimeWindowForChecksMillis, orParserMaxErrorNumberThreshold.StuckParserWaitTimeoutMillis– For a parser to fail with a timeout exception, its parse time must exceed this threshold. The value can be any integer, representing milliseconds.ParserMaxErrorTimeWindowForChecksMillis– The intervals in which your system checks the internal error statistics. The value can be any integer, representing milliseconds.ParserMaxErrorNumberThreshold– For a parser to be paused, the number of errors it accumulates must exceed this threshold. The value can be any integer, representing number of errors.
Save
custom_lime_config.conf.Restart Log Ingestion and Messaging Engine (LIME):
Source the shell environment:
source /opt/exabeam/bin/shell-environment.bash
Restart LIME:
lime-stop; lime-start
Disabled Event Types
When a high volume user or asset amasses a large number of events of a certain event type, and that event type contributes to a large portion of the overall event count for that user (typically 10M+ events in a session) the event type is automatically disabled and listed here.
Note
You are also shown an indicator when Advanced Analytics determines that the event type is problematic and disables it for the entity. The affected User/Asset Risk Trend and Timeline accounts for the disabled event type by displaying statistics only for the remaining events.
Disabled event types are displayed on the System Optimization tab of the System Health page. You can see a list of all event types that have been disabled, along with the users and assets for which they have been disabled for.
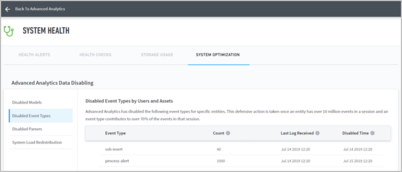 |
The Disabled Event Type by Users and Assets table is sorted first alphabetically by event type, then sorted by latest update timestamp.
The table includes columns with the following categories:
Event Type – The disabled event type.
Count – Last recorded total number of events for this entity.
Last Log Received – Date and time of the event that triggered the disabling of this event type for the specified entity.
Disabled Time – Date and time for when the event type was disabled for this entity.
You can also view disabled event types for an entity in metadata_db. Here is a sample disabled event types collection:
> db.event_
db.event_count_stats_collection db.event_disabled_collection
mongos> db.event_disabled_collection.findOne()
{
"_id" : ObjectId("5ce346016885455be1648a0f"),
"entity" : "exa_kghko5dn",
"last_count" : NumberLong(53),
"disabled_time" : NumberLong("1558399201751"),
"last_event_time" : NumberLong("1503032400000"),
"is_entity_disabled" : true,
"sequence_type" : "session",
"disabled_event_types" : [
"Dlp-email-alert-in",
"Batch-logon",
"Remote-access",
"Service-logon",
"Kerberos-logon",
"Local-logon",
"Remote-logon"
]
}Configure Thresholds for Disabling Event Types
Hardware and Virtual Deployments Only
When an entity's session has 10 million or more events in a session and an event type contributes to 70% or more of the events in that session, then that event type is disabled. If no single event type accounts for over 70% of the total event count in that session, then that entity is disabled. These thresholds, EventCountThreshold and EventDisablePercentage are configurable.
To configure the thresholds, navigate to the Container section located in the exabeam_default.conf file at /opt/exabeam/config/default/exabeam_default.conf.
All changes should be made to /opt/exabeam/config/custom/custom_exabeam_config.conf:
Container {
...
EventCountThreshold = 10000000 // Martini will record the user as top user once a session or a sequence has more than
// 10 million events
TopNumberOfEntities = 10 // reporting top 10 users and assets
EventDisablePercentage = 0.7 // a single event type that accounts for 70% of all event types for a disabled user
EventCountCheckPeriod = 60 minutes
}Acceptable values for EventCountThreshold are 10,000,000 to 20,000,000 for a typical environment. EventDisablePercentage can be a percentage decimal value between 0.1 to 0.9.
Manually Redistribute System Load
Hardware and Virtual Deployments Only
You can opt to manually configure the system load redistribution by creating a manual config section in custom_exabeam_config.conf.
To configure manual redistribution:
Run the following query to get the current distribution in your database:
mongo metadata_db --eval'db.event_category_partitioning_collection.findOne()'Taking the returned object, create a manual config section in
/opt/exabeam/config/custom/custom_exabeam_config.conf.Edit the configuration to include all the hosts and event categories you want.
Choose which categories should be shared by certain hosts by using
trueorfalseparameter values after “Shared =”.For example, the below section shows that host 2 and 3 both share the web event category. All other categories, which are marked as
Shared = “false”, are owned solely by one host.
Partitioner {
Partitions {
exabeam-analytics-slave-host3 = [
{
EventCategory = "database",
Shared = "false"
},
{
EventCategory = "other",
Shared = "false"
},
{
EventCategory = "web",
Shared = "true"
},
{
EventCategory = "authentication",
Shared = "false"
},
{
EventCategory = "file",
Shared = "false"
}]
exabeam-analytics-slave-host2 = [
{
EventCategory = "network",
Shared = "false"
},
{
EventCategory = "app-events",
Shared = "false"
},
{
EventCategory = "endpoint",
Shared = "false"
},
{
EventCategory = "alerts",
Shared = "false"
},
{
EventCategory = "web",
Shared = "true"
}
]
}
}Automatically Redistribute System Load
Exabeam can automatically identify overloaded worker nodes, and then take corrective action by evenly redistributing the load across the cluster.
This redistribution is done by measuring and comparing job completion time. If one node finishes slower by 50% or more compared to the rest of the nodes, then a redistribution of load is needed. The load is then scheduled to be rebalanced by event categories.
You can enable automatic system load redistribution on the System Optimization tab of the System Health page. This option is enabled by default. Doing so allows the system to check the load distribution once a day.
Note
It is not recommended that you disable the system rebalancing option as it will result in uneven load distribution and adverse performance impacts to the system. However, if you choose to do so, you can configure manual redistribution to avoid such impacts.
You must restart the Exabeam Analytics Engine for any changes to System Rebalancing to take effect.
The System Load Redistribution tab shows an indicator when a redistribution of load is needed, is taking place, or has completed. The rebalancing process can take up to two hours. During this time you may experience slower processing and some data may not be available. However, the system resumes normal operations once redistribution is complete.
Automatic Shutdown
If the disk usage on an appliance reaches 98%, then the Analytics Engine and log fetching will shut down automatically. Only when log space has been cleared and usage is below 98% will it be possible to restart.
Users can restart either from the CLI or the Settings page.